



2、理想的VLM模型是基于开源大语言模型训练的,里面海量的互联网二级图文数据做预训练,但是在3D空间理解和驾驶知识方面是有所不足的。
3、自动驾驶芯片如Orin-X和Thor-U它的内存带宽和算力是不及服务器GPU的,限制了模型的参数量和能力提升,也不能实现高效推理。
4、驾驶行为的学习更多的依赖于transformer进行回归建模,但这种方法难以处理人类驾驶行为的多模态性。
结合上述四点问题,理想汽车的解决方案是,端到端模型和VLM模型合二为一,同时学习像GPT o1和DeepSeek R1一样,利用思维链的方式让模型自己学会快慢思考,同时赋予模型强大的3D空间理解能力和行为生成能力。
这也就是理想汽车发布的VLA模型MindVLA。而理想汽车官方将其解释为:“VLA是视觉语言行为大模型,它将空间智能、语言智能和行为智能统一在一个模型里,VLA是Physical AI的最新范式,它赋予自动驾驶这样的物理系统感知思考和适应环境的能力。”
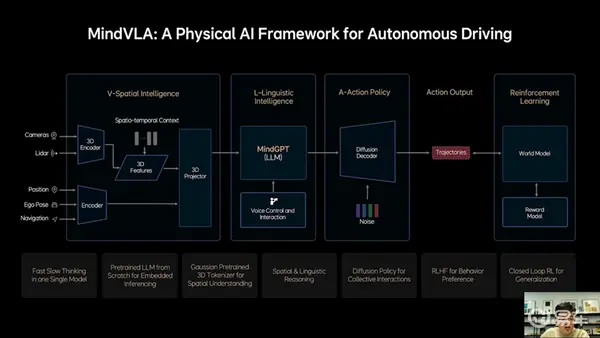
关于MindVLA模型,首先要知道的是,理想智驾工程团队没有简单地把端到端和VLM两个模型直接揉在一起,而是所有的模块都全部重新设计。
“3D空间编码器通过语言模型和逻辑推理结合在一起后给出合理的驾驶决策,并输出一组Action token,最终通过diffusion进一步优化出最佳的驾驶轨迹。这里所谓的Action token是对周围环境和自车驾驶行为的编码,整个模型推理过程都要发生在车端,而且要做到实时运行。”贾鹏解释了这张图的逻辑。
从这张图可以看到,摄像头和激光雷达传感器是直接输入到3D空间编码器,再结合时空上下文转换为3D特征,而位置信息、自车姿态、导航信息输入到常规编码器,两者合一传递到3D Projector进一步将特征映射到特定空间,比如BEV。这一模块就被称为3D空间智能模块,也就是Vision的部分。
接下来的L-Linguistic Intelligence就是语言智能。这一块是和之前端到端+VLM完全不同的地方,之前是VLM读出来之后传递给端到端系统做判断,而现在MindVLA则是输出3D表征到特定空间之后,让理想自己训练的大语言模型MindGPT去理解这些空间信息,然后做出判断、进行行为指令输出。
这里的指令输出按照理想汽车的解释会有两种模式:一个是慢输出,也就是CoT思维链思考过后的结果;一种是快输出,不经过思维链直接输出Action token。
这里还有一个能力是,增加了语音控制和互动的能力,是直接把指令给到大语言模型,然后模型会自动拆解任务,再结合3D空间智能进行Action token输出。
在Action这一步,理想汽车还加入了Diffusion模型,这里可解释为理想汽车的MindVLA借助Diffusion模型不仅生成自车的轨迹,还预测其他车辆和行人的轨迹,大大提升了标准模型在复杂交通环境中的博弈能力。
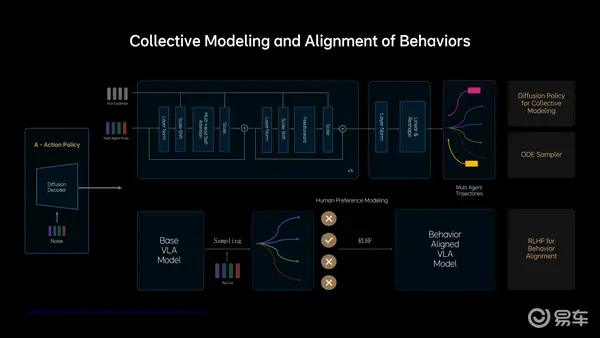
并且Diffusion还有一个巨大的优势,是可以根据外部的条件输入改变生成结果——如果你使用过AI生成图片就知道,漫画风格、写实风格是可以有不同参数指令来控制——这时候你就可以要求MindVLA有不同的驾驶风格,比如开快点、开慢点、激进一点、保守一点等等,而不会像现在的端到端可能就只有一种风格。
以上就基本解释了理想MindVLA模型的架构和训练逻辑,显然它是一个比端到端+VLM更加先进、更加拟人、并且还带有时空预测能力的全新智驾模型。
但是这其中要解决的工程问题也很多,技术要点理想没有展开,只是谈到了几个技术突破:
1、不同于之前依赖监督学习的BEV+占用网络3D表征,理想MindVLA使用了3D高斯(3D Gaussian)这一优良的中间表征,可以实现自监督训练,极大提升了下游任务性能。
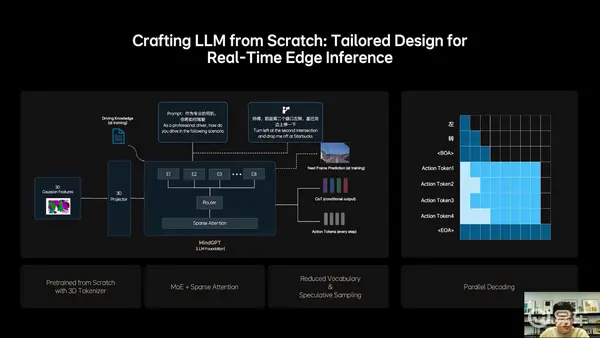
2、理想从0开始设计和训练了适合MindVLA的LLM基座模型,采用MoE混合专家架构,引入Sparse Attention(稀疏注意力),实现模型稀疏化,保证模型规模增长的同时,不降低端侧的推理效率。
基座模型训练过程中,理想加入大量3D数据,使模型具备3D空间理解和推理能力,减少了文史类数据的比例。为了进一步激发模型的空间智能,理想加入了未来帧的预测生成和稠密深度的预测等训练任务。